ch1.intro_to_ds_infra
Introducing data science infrastructure
Why data science infrastructure?
What is the main argument for needing infrastructure in data science?
- Infrastructure enables scaling, streamlining, and supporting various phases of data science projects.
- Like dairy production, small-scale data science can work without infrastructure, but scaling volume, velocity, validity, and variety requires structured systems.
How does the dairy analogy help explain infrastructure needs?
- Early dairy farming needed little infrastructure for small-scale production.
- Scaling operations introduced challenges: distribution (velocity), variety of products, and product stability (validity).
- Industrial dairy systems evolved to manage volume, velocity, and variety, mirroring what data science infrastructure must support.
What are the key concepts (the 4 Vs) used to evaluate data science infrastructure needs?
- Volume: Quantity of data and projects.
- Velocity: Speed of data movement and project execution.
- Variety: Diversity in data types and project outputs.
- Validity: Trustworthiness and robustness of results.
Even small projects benefit from consistent infrastructure, especially in production settings.
- To increase productivity of data scientists by providing tools that:
- Enable more projects (volume)
- Support varied use cases (variety)
- Accelerate time to delivery (velocity)
- Ensure reliable outputs (validity)
What does the life cycle of a data science project typically involve?
- Problem definition: A data scientist is tasked with solving a business problem (e.g., predicting customer lifetime value).
- Initial experimentation:
- Formulates hypotheses.
- Uses tools like Jupyter, R, Julia, MATLAB, or Mathematica.
- Prototyping:
- Builds models using tools like Scikit-Learn, PyTorch, TensorFlow, Stan.
- Data access:
- Starts with static samples.
- Scaling to large datasets or dynamic pipelines adds complexity.
- Execution environment:
- May begin on local machines.
- Collaboration and performance needs push toward cloud/shared servers.
- Production integration:
- Notebook prototypes must be integrated into business systems.
- Often requires deploying models as microservices.
- Evaluation and iteration:
- Stakeholders review results.
- Feedback loop leads to refinement or new project cycle.
What are the essential commonalities of all data science/ML projects?
- Technical: All require handling data and computations.
- Software engineering: Production deployment is crucial in applied settings.
- Human process: Involves experimentation and iteration.
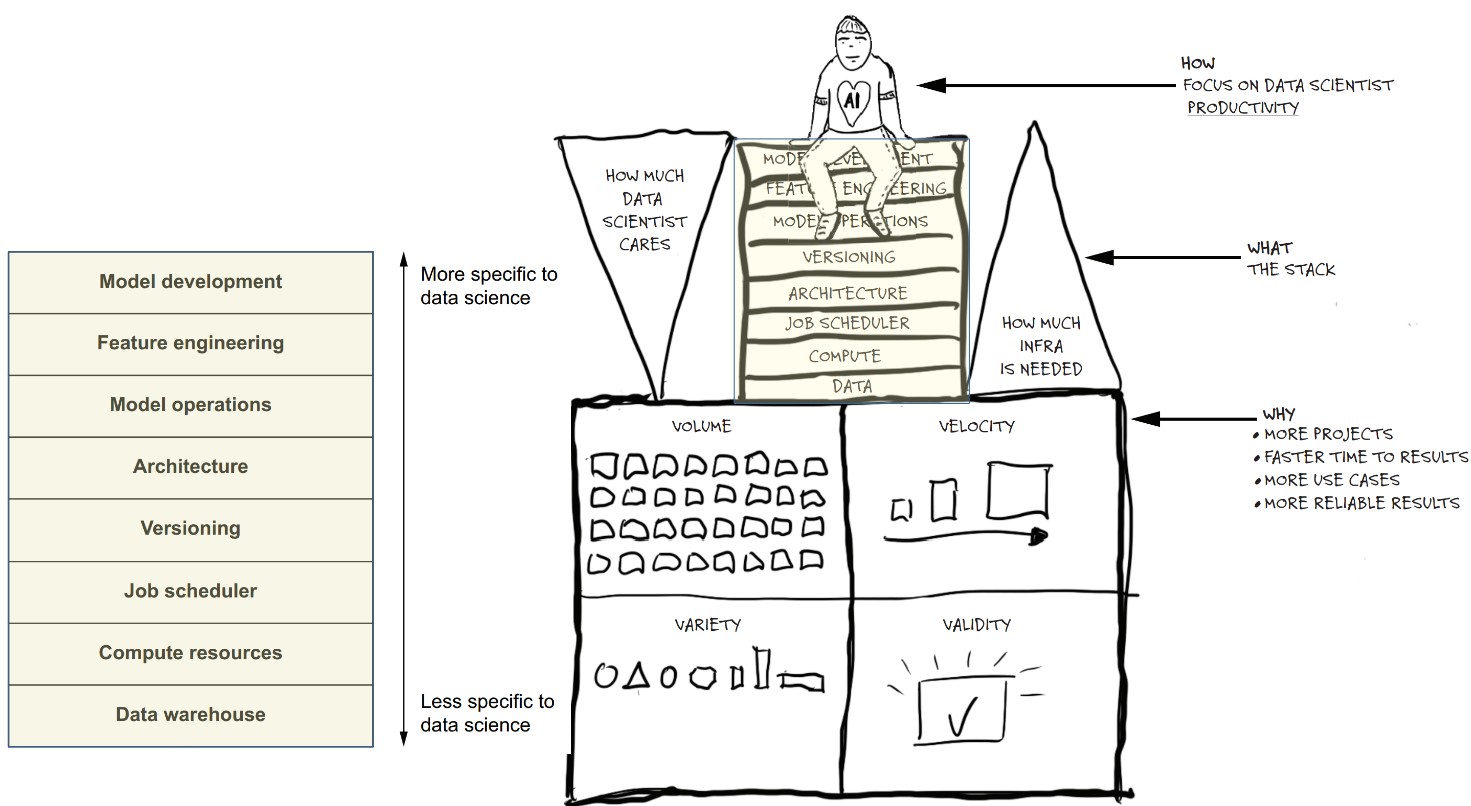
What are the main components of the data science infrastructure stack?
-
Data Warehouse:
- Centralized storage of input data, serving as a common source of truth.
- Prevents inconsistencies caused by multiple, separate data stores.
- Discussed in Chapter 7.
-
Compute Resources:
- Executes data transformations and model training.
- Must handle diverse workloads (CPU, GPU, high memory).
- Covered in Chapters 4 and 5.
-
Job Scheduler:
- Automates recurring tasks like model retraining and batch predictions.
- Structures workflows with dependencies between steps.
- Addressed in Chapters 2, 3, and 6.
-
Versioning:
- Supports iteration by tracking and managing multiple versions of code, data, and models.
- Enables disciplined experimentation (e.g., A/B testing).
- Explored in Chapters 3 and 6.
-
Architecture:
- Provides scaffolding and best practices for building maintainable, production-grade applications.
- Allows data scientists to operate autonomously with minimal engineering support.
- Implemented through frameworks like Metaflow (introduced in Chapter 3).
-
Model Operations (Model Ops):
- Ensures deployed models are reliable, observable, and maintainable.
- Deals with monitoring, error detection, and handling model failures.
- Has unique challenges due to probabilistic and evolving nature of models.
- Discussed in Chapters 6 and 8.
-
Feature Engineering:
- Transforms raw data into model-ready inputs.
- Involves selecting, cleaning, and processing data.
- Should be efficient for both human productivity and system performance.
- Discussed in Chapters 7 and 9.
-
Model Development:
- Creation and training of mathematical models.
- Uses libraries like Scikit-Learn, TensorFlow, etc.
- The infrastructure here is lightweight to allow flexibility.
- Represents a small but essential part of the entire system.
How are the layers in the stack organized?
- Bottom layers (e.g., data, compute, scheduling): General-purpose, foundational for any system.
- Top layers (e.g., feature engineering, model development): More specific to data science work.
- Each layer builds on the lower ones and supports more specialized tasks.
- Even though different teams may implement components differently, the need for each layer is nearly universal.
- Omitting any layer leads to inefficiencies, technical debt, or inability to scale.
- Provides a mental model for designing systems that deliver robust, scalable data science applications.
How does the infrastructure stack support the full life cycle of a data science project?
-
Goal: Support every stage of a data science project—from initial development through ongoing iteration.
-
Three core themes mapped to stack layers:
- Data & Compute (Bottom layers):
- Required for every project, independent of domain.
- Provide foundational capabilities like data access and execution power.
- Software Architecture (Middle layers):
- Governs how components are executed, integrated, and deployed.
- Involves building pipelines, deploying models, and distributing outputs.
- Modeling & Feature Work (Top layers):
- Core data science activities like modeling and transforming input data.
- Evolve quickly due to experimentation and iteration.
- Data & Compute (Bottom layers):
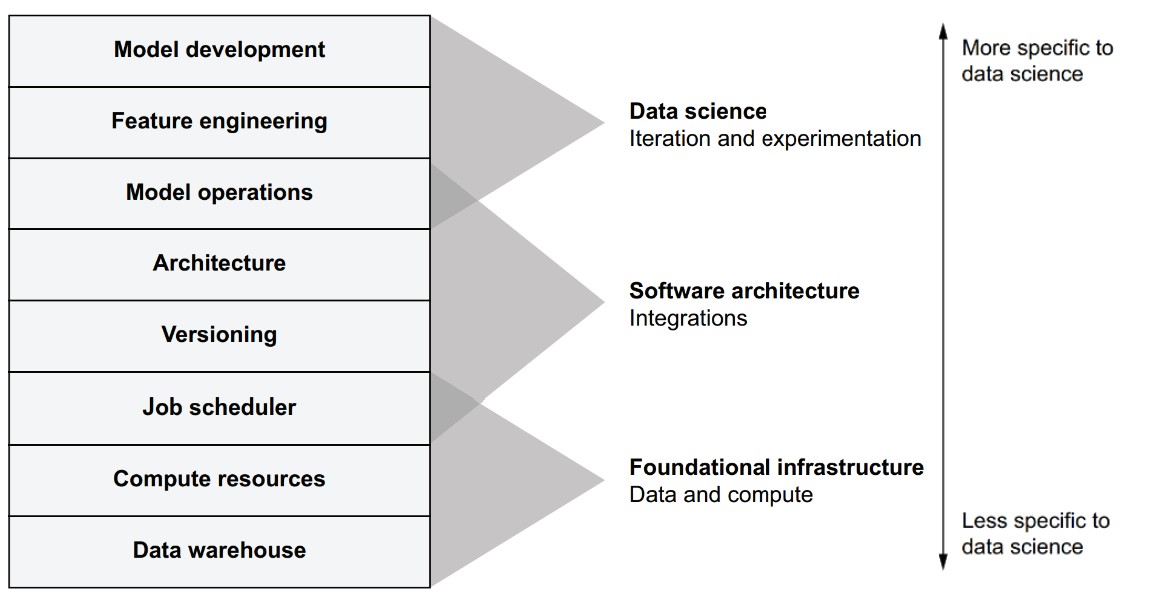
- Important Note: The stack is a blueprint for infrastructure design. Users (data scientists) should not need to manage or even be aware of stack boundaries—everything should feel unified and seamless.
What if your project is highly specialized? Is generalized infrastructure still applicable?
-
One size doesn't fit all—some applications require custom infrastructure:
-
Generalized infrastructure is better when:
- You have many applications or diverse use cases (e.g., a bank or large enterprise).
- You want to support experimentation and increase productivity at scale.
-
Hybrid approach:
- Use custom infrastructure for specialized, high-performance applications.
- Use generalized infrastructure for the broader range of typical business use cases.
-
Custom applications typically require more resources and slow down iteration due to complexity and limited expertise.
-
Generalized infrastructure enables optimizing for the four Vs (volume, velocity, variety, validity) across many projects.
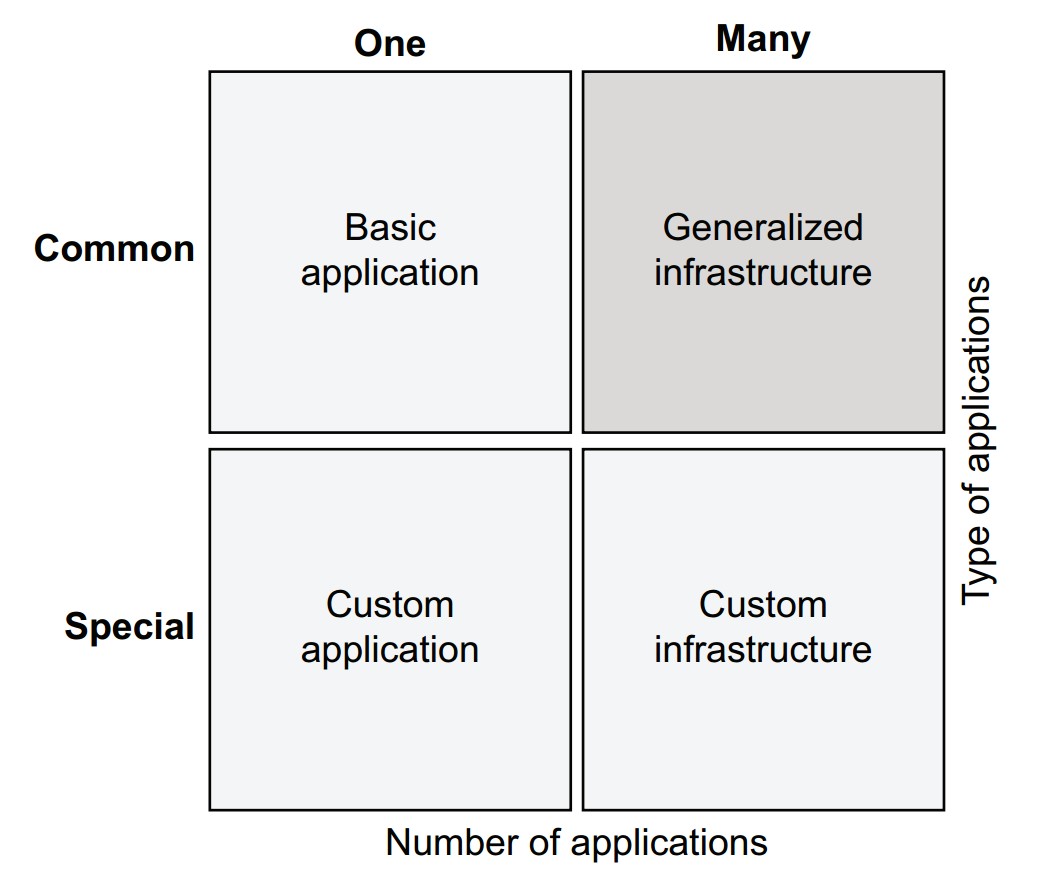
Metaflow can help unify infrastructure across these layers
- Supports multiple stack layers.
- Provides a coherent experience for data scientists.
- Can be used as-is or adapted with other tools to build a custom infrastructure.
Why good infrastructure matters
What makes building data science infrastructure complex?
-
Scale and interdependence:
- Production-grade ML applications (e.g., YouTube recommendations, ad optimization) are extremely complex, involving many subsystems and millions of lines of code.
- These systems resemble factories: interconnected pipelines, constant data flows, parallel model versions, and orchestration across distributed compute environments.
-
Multiple, evolving systems:
- Projects involve many models, data pipelines, versions, and teams.
- Environments must be isolated to avoid interference.
- All of this operates in real-time or near-real-time, under tight reliability and performance expectations.
-
Complexity increases with application variety:
- Most organizations have many data science applications, each with different needs (e.g., recommendation, marketing attribution, logistics optimization, forecasting).
- Applications are often interdependent, further compounding complexity.
How should this complexity be managed?
-
Infrastructure goals:
- Make managing complexity a first-class concern.
- Help data scientists remain productive despite system complexity.
- Reduce operational burden via automation and orchestration.
-
Avoiding incidental complexity:
- Focus on simplicity—remove unnecessary complexity that doesn’t solve real problems.
- Watch for:
- Boilerplate code: exists just to satisfy frameworks.
- Spaghetti pipelines: messy, unstructured workflows.
- Dependency hell: tangled, changing dependencies.
- Organizational boundaries can introduce unnecessary technical complexity (e.g., handoffs between roles).
-
Best practice: Favor simplicity without oversimplifying. Use the principle:
“Everything should be made as simple as possible, but no simpler.”
How can we build effective infrastructure without excessive engineering effort?
-
Leverage existing platforms:
- Most infrastructure components are already technically possible using modern platforms.
- Your job is to make them easy to use, not just possible.
-
The “valley of complexity”:
- Many systems stay on the “possible” side—technically functional but hard to use.
- Crossing to the “easy” side requires integration, abstraction, and thoughtful design.
- Infrastructure should bridge this gap, enabling productivity, not just feasibility.
What role does cloud computing play in building infrastructure?
-
Cloud platforms (AWS, GCP, Azure):
- Provide virtually unlimited compute and storage.
- Eliminate need to manage low-level hardware or scaling logistics.
- Offer free tiers and pay-as-you-go pricing, making it cost-effective to prototype.
-
Benefits of cloud-based infrastructure:
- Shifts mindset from scarcity (limited compute/storage) to abundance.
- Enables design focused on cost-effectiveness and productivity, rather than resource efficiency alone.
-
Cloud strategy in this book:
- Assumes access to cloudlike infrastructure (public or private cloud).
- Emphasizes building a custom stack using open source and cloud services.
- Rejects one-size-fits-all platforms; instead favors flexibility and usability.
- Allows focusing development effort on unique business value and data scientist productivity.
Human-centric infrastructure
How does infrastructure improve organizational productivity in data science?
-
Primary aim: Maximize productivity by enabling more projects, faster delivery, reliable results, and broader domain coverage.
-
Key bottlenecks without effective infrastructure:
- Volume: Too few data scientists to handle more projects.
- Velocity: Building production-ready systems is too time-consuming.
- Validity: Prototype models fail in production due to unexpected data issues.
- Variety: Incompatibilities between tools, languages, and system requirements limit expansion to new use cases.
-
Insight: The main constraint is not the technology, but human limitations—time, bandwidth, and context-switching.
What does it mean to build human-centric infrastructure?
- Human focus: Infrastructure should make data scientists more productive—not just serve machines.
- Design principles:
- Prioritize expressiveness and usability over raw performance.
- Minimize cognitive overhead—make the stack feel seamless.
- Optimize human time over compute time.
How does the principle of freedom and responsibility apply to infrastructure?
-
Concept origin: From Netflix’s internal culture, emphasizing autonomy with accountability.
-
Application in infrastructure:
- Data scientists:
- Granted freedom in upper stack layers (modeling, feature engineering).
- Expected to take some responsibility in mid-layers (architecture, versioning).
- Infrastructure team:
- Has control over foundational layers (compute, storage, job scheduling).
- Less involved in domain-specific modeling decisions.
- Data scientists:
-
Goal: Align individual autonomy with company-wide goals (volume, velocity, variety, validity) by providing a well-designed, flexible stack.
How can infrastructure reduce coordination overhead in data science projects?
-
Current reality:
- Many roles involved per project: data scientist, ML engineer, data engineer, DevOps, app engineer, platform engineer.
- Also includes business owners, product managers, and project managers.
-
Challenges:
- High communication and coordination costs.
- Lack of staffing for every role in every project.
-
Infrastructure goal:
- Empower data scientists to take on multiple technical roles autonomously:
- Build and deploy models at scale.
- Manage data pipelines.
- Monitor production models.
- Reduce dependency on multiple specialists for every project.
- Empower data scientists to take on multiple technical roles autonomously:
What is the outcome of this approach?
- Greater autonomy: A single data scientist can carry a project from start to finish.
- Scalability: Fewer people can execute more projects in parallel.
- Focus retention: Data scientists can stay concentrated on core data science tasks, not infrastructure burdens.
- Flexibility: Central teams still support complex projects, but many simpler or smaller efforts can proceed independently.