module3_part2_ml_boosting_algorithms
Module 3- Part 2- ML boosting algorithms XGBoost, CatBoost and LightGBM
-
Classification problem setup:
- Goal: Classify whether a person will default on their credit card using features like income, balance, age, gender, etc.
- Target variable: Default status (yes/no).
-
Four fundamental questions in decision tree-based models:
-
Which feature and cutoff to start with?
- Determine the initial feature for the tree (e.g., income or balance).
- Decide the cutoff value for splitting the data into branches (e.g., income threshold).
- The key is maximizing information gain.
-
How to split the samples?
- Choose a method for splitting samples, such as:
- Pre-sorted or histogram-based splits.
- Greedy methods or other strategies.
- Choose a method for splitting samples, such as:
-
How to grow the tree?
- Decide the tree growth strategy, such as:
- Depth-wise growth.
- Leaf-wise growth.
- Symmetric growth.
- Different growth methods lead to different boosting models.
- Decide the tree growth strategy, such as:
-
How to combine the trees?
- Decide how to aggregate multiple trees:
- Bagging (Bootstrap Aggregation).
- Boosting techniques (e.g., XGBoost, CatBoost, LightGBM).
- Decide how to aggregate multiple trees:
-
Which feature and cutoff to start with?
-
Goal in a decision tree:
- Maximize purity or minimize impurity at each decision node to achieve better splits.
-
Metrics for determining splits:
- For regression trees, the metric is Mean Squared Error (MSE).
- For classification trees, there are several metrics:
- Error rate
- Entropy / Cross entropy
- Gini index
-
Example:
- Given two features (x1 and x2) with 20 observations (10 red, 10 blue), we need to:
- Decide which feature to split on.
- Determine the best cutoff point.
- In the example, x2 seems to be the better feature to split on, and the red cutoff line (that separates all red and blue points perfectly) is the best split, resulting in an error rate of zero.
- Given two features (x1 and x2) with 20 observations (10 red, 10 blue), we need to:
-
Choosing a decision criterion for classification:
- Error rate is rarely used because it is less sensitive to changes in probability.
- Entropy and Gini index are more commonly used.
- Entropy is more sensitive to changes in probabilities compared to Gini, making it preferable when higher sensitivity is needed.
- Gini index is computationally faster, though the difference is usually minor unless dealing with very large datasets.
-
Recommendation:
- For most cases, it’s best to let the algorithm decide between cross-entropy or Gini index using techniques like grid search to find the best-performing criterion during cross-validation.
How to split the samples?
1. Pre-sorted and Histogram-based Splitting:
- Process:
- Sorts the data and creates histograms before splitting.
- Cutoffs are determined based on bins in the histogram.
- Advantages:
- Fast: Reduces the number of splits to consider, speeding up the process.
- Disadvantages:
- Less accurate: Not all possible cutoffs are considered, potentially missing better splits.
2. Gradient-based One-sided Sampling (GOSS):
- Process:
- Uses gradient information to assign weights to samples.
- Samples with high gradients (indicating more room for improvement) are kept.
- Samples with low gradients (already well-predicted) are randomly sampled.
- Advantages:
- Focuses on the most critical samples with large gradients, improving model performance where it matters most.
- Disadvantages:
- Could underutilize samples with low gradients, which might still provide useful information.
3. Greedy Method:
- Process:
- At each step, selects the best split without considering future splits.
- The decision is made based on the current split, without looking ahead.
- Advantages:
- Simple and fast decision-making at each node.
- Disadvantages:
- Suboptimal trees: Since future splits are not considered, this method may result in suboptimal tree structures.
These three methods are commonly used in boosting algorithms like XGBoost, CatBoost, and LightGBM, each with its trade-offs between speed and accuracy.
How to grow a tree?
- 1. Depth-wise Growth:
- The tree grows by repeatedly splitting the data based on the feature with the highest information gain.
- Splitting continues until a pre-specified maximum depth is reached.
- The tree structure is balanced, meaning all leaf nodes are at the same depth.
- Example:
- Depth = 1: 2 terminal nodes.
- Depth = 2: 4 terminal nodes.
- Depth = 3: 8 terminal nodes.
- Splits at each depth level may involve different features, such as "age > 25" at one level and "balance < 100" at another.
- 2. Leaf-wise Growth:
- Data is split repeatedly based on the feature with the highest information gain until each leaf node contains only one class.
- The tree structure is unbalanced, with some branches deeper than others.
- Example:
- The algorithm focuses on a single branch, going further down until 100% purity is reached.
- This method tends to create deeper trees for certain branches to achieve full class purity.
- 3. Symmetric Growth:
- Like the previous methods, splits are made based on the feature with the highest information gain.
- This method results in a balanced tree, similar to the depth-wise approach.
- However, the big difference is that at each level, the same feature and split cutoff are applied across all nodes.
- Example:
- If a split is "balance > 100" at one node, it will be the same at all other nodes on the same level.
- The stopping criteria can vary, such as a minimum number of samples per terminal node.
- Key Differences:
- Depth-wise: Balanced, different splits at each level.
- Leaf-wise: Unbalanced, purity-focused with deep branches.
- Symmetric: Balanced, with identical splits at each level.
How to combine the trees?
1. Bagging (Bootstrap Aggregation):
- Process:
- Create multiple slightly different copies of the training data by bootstrapping (sampling with replacement).
- Apply a weak learner (e.g., decision trees) to each copy of the dataset independently.
- Each weak learner generates a prediction (e.g., Y hat 1, Y hat 2, Y hat 3).
- Combine the predictions:
- Regression: Take the mean of the predictions.
- Classification: Use majority voting.
- Key points:
- Trees are independent from each other.
- Can be processed in parallel.
2. Boosting:
- Process:
- Start with the original training data.
- Iteratively apply a weak learner (e.g., decision tree) to correct the errors of the previous model.
- After each tree, calculate the residuals (the part not explained by the current tree).
- Use these residuals as input for the next weak learner.
- Continue this process iteratively, each model trying to correct the errors of the previous ones.
- The final output is a weighted combination of all the models (e.g., λ Y1 + λ² Y2 + ...).
- Key points:
- Trees are dependent on each other, as each tree uses information from the previous one.
- Models are combined using a shrinkage factor (λ) to prevent overfitting.
Main Difference:
- Bagging creates independent trees and combines their outputs in parallel.
- Boosting creates dependent trees, where each tree focuses on correcting the errors of the previous ones, leading to a more sequential process.
Development of XGBoost
The Need to Go Beyond Decision Trees:
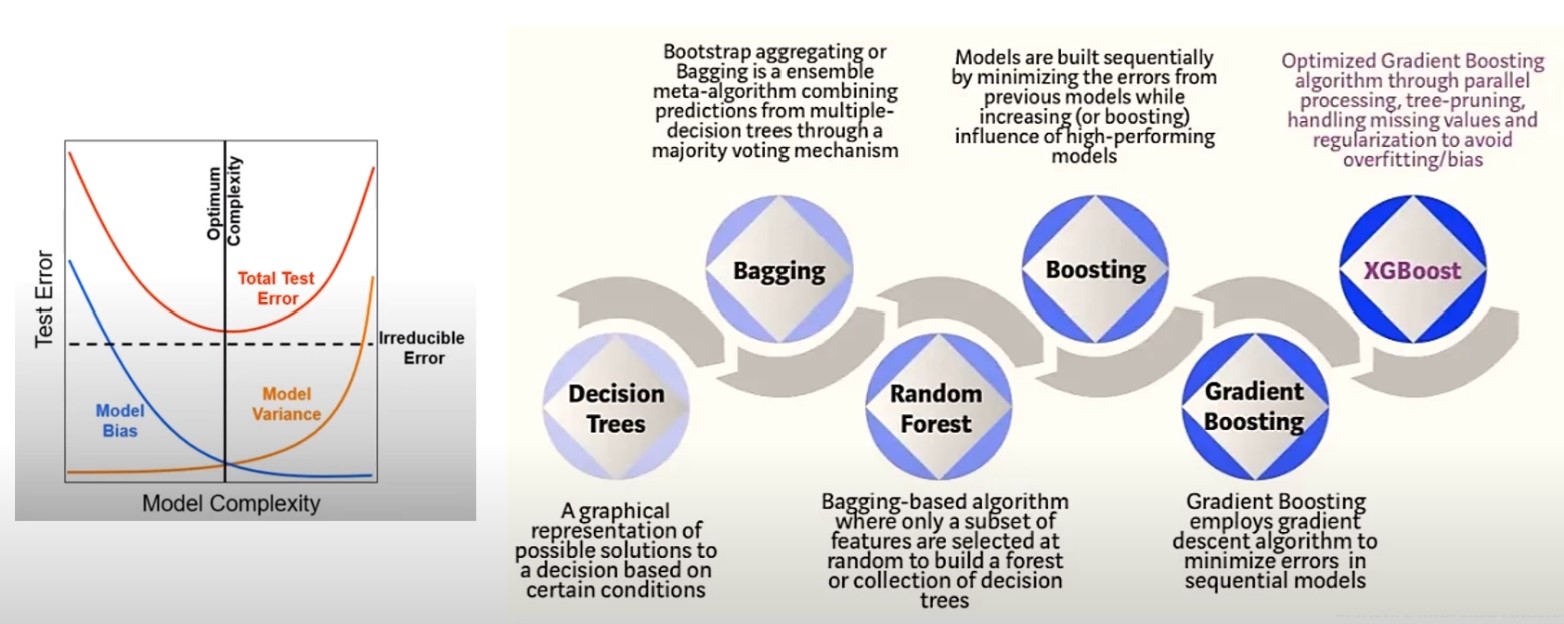
- Decision Trees:
- Advantages: Simple, interpretable, and easy to implement.
- Challenges: When made very deep (bushy), they have low bias (capture training data well) but high variance, leading to overfitting.
- Pruning (cost-complexity pruning) can help balance bias and variance, but performance remains suboptimal for complex tasks.
Bagging (Bootstrap Aggregation):
- Approach: Combine multiple decision trees built on different bootstrapped samples of the training data.
- Goal: Reduce model variance by averaging over several independent trees.
- Result: Typically better performance than a single decision tree due to reduced variance.
- Limitation: Trees in bagging may still be correlated if one feature (e.g., balance) dominates the splits.
Random Forests:
- Approach: Introduces randomization to reduce tree correlation.
- Key idea: At each split, randomly select a subset of features to choose the best split.
- Benefit: This randomization leads to de-correlated trees, further reducing variance.
- Result: Random forests reduce variance even more effectively than bagging but may still struggle with high bias.
Boosting:
- Approach: Instead of building large, complex trees, boosting starts with small, simple trees (often depth 1 or 2) and builds trees sequentially, each correcting the errors of the previous one.
- Focus: Boosting reduces bias by focusing on improving predictions for data points that are poorly predicted by previous trees (i.e., residuals).
- Result: It balances bias and variance by iteratively refining the model, leading to lower bias with controlled variance.
Gradient Boosting:
- Enhancement: Weights each observation based on its gradient with respect to the cost function.
- High gradient: Indicates poorly predicted samples; focus more on them in the next tree.
- Low gradient: Indicates well-predicted samples; focus less on them.
- Result: Improves accuracy by focusing learning efforts where needed most.
XGBoost:
- Extension of Gradient Boosting: Optimized for speed and performance.
- Key features:
- Parallel processing: Although boosting is inherently sequential, XGBoost introduces optimizations to speed up computations.
- Regularization: L1/L2 regularization helps prevent overfitting by penalizing overly complex models.
- Handling missing data: XGBoost efficiently handles sparse datasets.
- Goal: Improve gradient boosting by making it faster and more efficient while maintaining high predictive accuracy.
- Key features:
Summary
- Decision Trees: Simple but prone to overfitting with high variance.
- Bagging: Reduces variance by averaging over independent trees but can result in correlated trees.
- Random Forests: Reduces tree correlation, leading to lower variance than bagging.
- Boosting: Focuses on reducing bias by sequentially correcting errors, leading to improved accuracy.
- XGBoost: Extends gradient boosting with optimizations for speed, regularization, and parallelism.
XGBoost Overview:
- Development: Created in 2014 by Tianqi Chen, XGBoost is an open-source gradient boosting library designed for speed and scalability in machine learning.
- Focus: Emphasizes performance and parallelization, building on the strength of gradient boosting models (GBM) while enhancing efficiency.
Key Features of XGBoost:
-
Built-in Cross-Validation:
- Automatically applies cross-validation at each boosted tree to prevent overfitting.
- This built-in functionality ensures that each tree’s performance is evaluated, enhancing generalization.
-
Efficient Handling of Missing Data:
- Handles missing data effectively, reducing data sparsity (which becomes an issue in high-dimensional datasets).
- Ensures that missing values are managed without the need for manual preprocessing.
-
Advanced Regularization:
- Adds extra layers of regularization (beyond decision tree methods like max depth and pruning).
- Includes L1 (Lasso) and L2 (Ridge) regularization, penalizing the model to avoid overfitting by adding a penalty term to the loss function based on the weights of terminal nodes.
-
Cache Awareness and Out-of-Core Computing:
- Cache Awareness: Performs computations in the cache memory, which is much faster than reading from the hard drive.
- Out-of-Core Computing: Optimized to handle large datasets by decomposing data and using fast cache memory for gradient calculations, resulting in a significant speed advantage.
-
Tree Pruning (Depth-First Approach):
- Uses a depth-first approach to build trees, where it allows the tree to grow to its maximum depth and then prunes back branches that do not contribute to positive gain.
- This differs from traditional GBM, which might stop splitting early if a negative loss is encountered.
-
Parallelization:
- XGBoost introduces parallelization in boosting, which is typically a sequential process.
- By parallelizing parts of the computation (e.g., finding the best split), XGBoost achieves faster training times compared to standard GBM.
Summary of XGBoost's Strengths
- Speed: Parallelization and cache optimization make it faster than traditional GBM.
- Regularization: L1 and L2 regularization provide extra control to prevent overfitting.
- Handling Large Datasets: Out-of-core computing allows XGBoost to handle large datasets efficiently. Here’s a concise explanation of LightGBM, its key features, and how it compares to other boosting algorithms like XGBoost and CatBoost:
LightGBM Overview:
- Development: Introduced by Microsoft in 2016, LightGBM is an open-source gradient boosting library designed for large-scale learning tasks.
- Focus: Known for its speed and efficiency, particularly when dealing with large datasets.
Key Features of LightGBM
-
Efficient for Large Datasets:
- Designed to handle large-scale datasets efficiently.
- Faster than many other gradient boosting algorithms, especially when data volume is high.
-
Handling Categorical Features:
- Advantage: LightGBM is better than XGBoost at handling categorical features, but it still requires preprocessing steps like one-hot encoding or ordinal encoding.
- CatBoost handles categorical features more efficiently without requiring as much preprocessing, which is a major advantage over LightGBM.
-
Other Common Features (with XGBoost and CatBoost):
- Handling Missing Values: Automatically manages missing values during training.
- Automatic Feature Selection: Selects important features without manual intervention.
- Model Ensembling: Combines multiple weak learners to build a strong model.
CatBoost Overview:
- Development: CatBoost, short for Category Boosting, was developed by Yandex in 2017 as an open-source gradient boosting library.
- Focus: Primarily designed to handle categorical features efficiently without requiring preprocessing like one-hot encoding or ordinal encoding, making it superior in this regard to both XGBoost and LightGBM.
Key Features of CatBoost
-
Direct Handling of Categorical Features:
- No Preprocessing Needed: CatBoost can handle categorical variables directly, eliminating the need for one-hot encoding or other preprocessing methods.
- This makes it particularly efficient for datasets with many categorical features, unlike XGBoost and LightGBM, which require some form of encoding.
-
Model Performance Enhancements:
- Similar to XGBoost and LightGBM, CatBoost includes:
- Handling Missing Values: Automatically manages missing values without manual intervention.
- Automatic Feature Selection: CatBoost selects the most important features during training.
- Model Ensembling: Combines weak learners into a stronger model through boosting.
- Similar to XGBoost and LightGBM, CatBoost includes:
-
Specific Design for Categorical Data:
- The unique approach to categorical feature handling gives CatBoost a performance advantage in tasks where categorical data is dominant.
- This direct handling of categorical data is what distinguishes CatBoost from its counterparts.
Comparison Table of XGBoost, LightGBM, and CatBoost
| Feature | XGBoost | LightGBM | CatBoost |
|---|---|---|---|
| Developer | Tianqi Chen (2014) | Microsoft (2016) | Yandex (2017) |
| Base Model | Decision Trees | Decision Trees | Decision Trees |
| Tree Growing Algorithm | Depth-wise (Leaf-wise also available) | Leaf-wise | Symmetric |
| Parallel Training | Single GPU | Multiple GPUs | Multiple GPUs |
| Handling Categorical Features | Requires encoding (manual) | Automated, but encoding still needed | Direct handling (no encoding needed) |
| Splitting Method | Pre-sorted and histogram-based | GOSS (Gradient-based One-sided Sampling) | Greedy method |
| Scalability | Fast, but less scalable | Most scalable | Good scalability |
High-Level Observations
-
XGBoost:
- Great for general boosting tasks but lacks efficient handling of categorical features and scalability compared to the other two.
-
LightGBM:
- Best suited for large-scale datasets, with highly scalable leaf-wise growth and support for multiple GPUs. Requires automated encoding for categorical features.
-
CatBoost:
- Best for datasets with many categorical features, as it directly handles them without needing encoding. It’s also fast and scalable with multi-GPU support.
Recommendations
- Use CatBoost if your dataset has many categorical variables.
- Use LightGBM for large-scale datasets that require scalability.
- Use XGBoost for general-purpose boosting, but consider the limitations with categorical data handling.
All three are strong contenders in terms of performance and often appear among the top models in competitions like Kaggle.